With a little bit of effort, we can make our markup more meaningful. But why put in extra time and resources to implement semantic HTML? Most users don’t read our HTML.
And they only care about what’s on the screen. Semantic HTML is really just for machines. They aren’t as smart as you and I, so we need to help them out.
An example of machines that benefit from semantic HTML are search engines. When search engines index our site, they interpret the content of our web pages based on our markup. This is what Google says about using semantic HTML (emphasis is mine):
Google (and other search engines) can use that data to index your content better, present it more prominently in search results, and surface it in new experiences like voice answers, maps, and Google Now.
Social media web services like Facebook, Pinterest, and Twitter love semantic markup. Especially when our users share our content on them. These web services take parts of our articles to display on their platform.
If we use semantic HTML, they’ll be able to do a better job. Language-translating tools examine our markup so they can convert our articles to another language. Good HTML markup can result in more accurate translations.
For example, there are subtle distinctions between American-English and British-English. People might be able to understand dialectical and idiomatic differences with ease. But machines might not.
Semantic HTML also enhances web accessibility. Assistive technologies like screen-reading software parse and interpret our HTML. With semantic HTML, people with special needs will be able to read and navigate our articles easier. That’s just the tip of the iceberg.
There are a gazillion other machines that look at our HTML and try to understand it. Heck, the Internet’s made up of a bunch of machines. They’re a big part of the Web.
We should try our best to feed them more meaningful data. OK so, by now, I’m hoping you’re on board. Now you want to use semantic HTML. Maybe on your blog.
Or in a CMS development project. Check out the boilerplate below.
HTML Template
Here’s a semantic HTML template for web content. It’s a good starting point/boilerplate.
Just fill in the blanks. It’s general enough so that it can work on many types of textual content. Blog posts, news articles, essays, and so on.
Update: This template was changed due to the incorrect use of the main and summary HTML elements. See this comment below.
<!DOCTYPE html> <html itemscope itemtype="https://schema.org/Article" lang="" dir=""> <head> <title itemprop="name"></title> <meta itemprop="description" name="description" content=""> <meta itemprop="author" name="author" content=""> </head> <body> <article> <header> <h1 itemprop="headline"></h1> <time itemprop="datePublished" datetime=""></time> <p><a itemprop="author" href=""></a></p> </header> <div itemprop="about"></div> <div itemprop="articleBody"> <!-- The main body of the article goes here --> </div> <footer> <time itemprop="dateModified" datetime=""></time> <section itemscope itemtype="http://schema.org/WebPage"> <!-- Section heading--> <h2></h2> <p><a itemprop="relatedLink" href=""></a></p> </section> </footer> </article> </body> </html>The HTML markup template uses semantic HTML elements (i.e. article, header, and footer).
Also, it uses structured data markup from Schema.org. Particularly the Article and WebPage schemas. Schema.org is a joint project by Google, Bing, and Yahoo!.
A goal of the project is to provide a way for search engines to better understand our content.
Example
Here’s a filled-out example:
<!DOCTYPE html> <html itemscope itemtype="https://schema.org/Article" lang="en" dir="ltr"> <head> <title itemprop="name">Article's Web Page Title</title> <meta itemprop="description" name="description" content="Short description of the article."> <meta itemprop="author" name="author" content="Author Name"> </head> <body> <article> <header> <h1 itemprop="headline">The Article's Headline</h1> <time itemprop="datePublished" datetime="1990-11-12">November 12, 1990</time> <p>By <a itemprop="author" href="#author-profile.html">Author Name</a></p> </header> <div itemprop="about">Summary of the article. This could be the lead, excerpt, abstract, or introductory paragraph.</div> <div itemprop="articleBody"> <p>The main body of the article goes here.</p> </div> <footer> <p>This article was updated on <time itemprop="dateModified" datetime="2015-03-01">March 30, 2015</time></p> <section itemscope itemtype="http://schema.org/WebPage"> <h2>Related Articles</h2> <p><a itemprop="relatedLink" href="#related-article.html">A Related Article</a></p> <p><a itemprop="relatedLink" href="#related-article-02.html">Another Related Article</a></p> </section> </footer> </article> </body> </html>Details
Let’s talk about the various parts of the HTML template.
Specifying Content Type, Language and Text Direction
The html element has four attributes:
itemscopeindicates that the Article schema is used throughout the entire HTML document.itemtypecontains the web address of the schema we’re using.langgives information on what language the content is written in. W3C says we should now use the language codes listed in the IANA Language Subtag Registry. For example, if the page is written in German, we should assign thelangattribute the value ofde.dirprovides information on the text direction of the article. You have two options here.diris either “left to right” (ltr) or “right to left” (rtl).If you want the browser to decide for you, take out the
dirattribute.
Semantic HTML Structure
To structure our content meaningfully, we use the following HTML elements according to their W3C specs.
| Element | Description |
|---|---|
article |
The article element represents a discrete piece of content that can stand on its own. In the boilerplate, it houses all of our visible content. |
header |
Introductory content is best structured as child elements of a header element. In the context of articles, introductory content can be the article’s headline, date of publication, and the author’s name. |
footer |
“A footer typically contains information about its section such as who wrote it, links to related documents, copyright data, and the like.” — 4.3.8 The footer element |
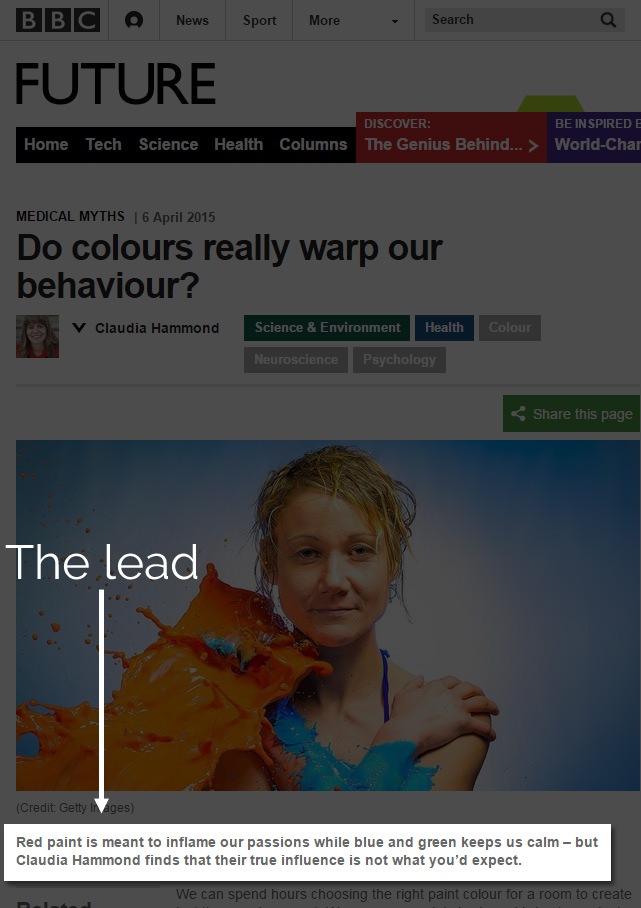 The BBC uses lead sentences on all of its articles.
The BBC uses lead sentences on all of its articles.
Structured Data
The boilerplate uses microdata to reinforce our semantic HTML structure.
And, if you’re concerned about using the new HTML5 elements, then you can replace them with well-supported elements like divs and spans and still be able to provide semantic information with microdata. Here are short descriptions of the microdata used in the HTML template.
| Microdata | Description |
|---|---|
name |
This property points to the name of an item. In our case, the item is the article.
The |
headline |
The article’s human-readable title. Some sites use a short, keyword-rich value for the <title> element because of SEO, and then a longer headline that describes the subject of the article. |
description |
A brief explanation of what the article is about. Assigning this property to the <meta name="description"> tag works well in most cases. |
author |
The content creator’s name.
In the HTML template, this is used in the |
datePublished |
This property lets us explicitly state that the <time> element in the header contains the date in which the article was posted. |
about |
This should be used on text that describes the subject of the article. It’s great for lead sentences/paragraphs. |
articleBody |
This property represents the main body of the article. |
dateModified |
You may want to let people know when the article was last reviewed and updated. If we want to give machines the same courtesy, we’ll need to use the dateModified property. This also gives web services a hint that they should update their index because the content has changed. |
relatedLink |
This property is used for links related to the article.The relatedLink property is part of the WebPage schema so we have to state that item type in a parent element. |
Using More Meaningful Markup
Like I said earlier, the HTML template is just a general starting point.
Consider using additional microdata (and other semantic HTML elements) that will make your content more meaningful. Schema.org has a ton of schemas for a wide variety of content types. Here are some examples:
- Blog posts:BlogPosting schema
- Comment sections: UserComments schema
- News stories:NewsArticle schema
- For sites that post lots of code examples:Code schema
See the full list of available schemas here.
Tips
Once you’re happy with your semantic HTML structure, test and validate it using Google’s Stuctured Data Testing Tool.  Also, the HTML template uses HTML5 elements. If you support a lot of users who are on outdated browsers, you’ll need to use a shiv such as Modernizr or HTML5 Shiv. Or, you can replace the HTML5 elements in the template with generic elements such as
Also, the HTML template uses HTML5 elements. If you support a lot of users who are on outdated browsers, you’ll need to use a shiv such as Modernizr or HTML5 Shiv. Or, you can replace the HTML5 elements in the template with generic elements such as div‘s.
Keep the microdata though.
Related Content

-
 President of WebFX. Bill has over 25 years of experience in the Internet marketing industry specializing in SEO, UX, information architecture, marketing automation and more. William’s background in scientific computing and education from Shippensburg and MIT provided the foundation for MarketingCloudFX and other key research and development projects at WebFX.
President of WebFX. Bill has over 25 years of experience in the Internet marketing industry specializing in SEO, UX, information architecture, marketing automation and more. William’s background in scientific computing and education from Shippensburg and MIT provided the foundation for MarketingCloudFX and other key research and development projects at WebFX. -

WebFX is a full-service marketing agency with 1,100+ client reviews and a 4.9-star rating on Clutch! Find out how our expert team and revenue-accelerating tech can drive results for you! Learn more
Make estimating web design costs easy
Website design costs can be tricky to nail down. Get an instant estimate for a custom web design with our free website design cost calculator!
Try Our Free Web Design Cost Calculator
Share this article


Web Design Calculator
Use our free tool to get a free, instant quote in under 60 seconds.
View Web Design CalculatorMake estimating web design costs easy
Website design costs can be tricky to nail down. Get an instant estimate for a custom web design with our free website design cost calculator!
Try Our Free Web Design Cost Calculator